1) 어떤 문제를 해결하고 싶은가
- 목표는 Transfer Learning에서 “task가 많아질수록 모델 저장/학습 비용이 task 수에 비례해 폭증”하는 문제를 줄이는 것이다.
- 대형 pre-trained model(예: BERT)을 각 downstream task마다 full fine-tuning하면, 사실상 task마다 새로운 모델 전체 사본이 필요해진다.
- online/streaming 환경(새 task가 순차적으로 계속 추가되는 환경)에서는,
- 과거 task를 다시 같이 학습하지 않고도(sequential training)
- 새 task를 추가하면서도
- 저장/메모리/배포 비용이 과도하게 증가하지 않는(parameter-efficient)
방식이 필요하다.
왜 이 문제가 중요한가
대형 backbone을 task마다 통째로 복제하면 총 저장량이 \(O(N)\)으로 증가한다(\(N\)=task 수).
클라우드/프로덕션에서는 “고객별, 도메인별, 기능별”로 task가 계속 늘어나는 경우가 흔하므로, 파라미터 효율(parameter efficiency)은 단순 연구 편의가 아니라 운영 비용/확장성의 핵심 제약이 된다.
2) 선행연구는 어땠는가
- 논문은 transfer 방법을 크게 feature-based transfer와 fine-tuning으로 정리하고, 이 둘이 “많은 task” 환경에서 갖는 비효율을 문제로 둔다.
- feature-based transfer
- pre-trained network \(\phi_w(x)\)에서 feature를 뽑고, 새 head \(\chi_v(\cdot)\)만 학습해 \(\chi_v(\phi_w(x))\) 형태로 푼다.
- 장점: backbone \(w\)를 공유 가능.
- 한계: head만으로는 task별로 필요한 표현 변형(representation adaptation)이 부족할 수 있다.
- fine-tuning
- task마다 \(w\) 자체를 업데이트한다.
- 장점: 성능이 강력하다.
- 한계: task마다 전체 파라미터가 달라져 compactness(총 저장량) 관점에서 매우 비효율적이다.
- feature-based transfer
- 논문은 multi-task learning과 continual learning도 대비한다.
- multi-task learning (MTL)
- 하나의 모델로 여러 task를 다루는 compact한 형태가 가능하다.
- 하지만 일반적으로 모든 task에 동시에 접근(simultaneous access)이 필요하고, online task arrival 설정과 맞지 않는 경우가 많다.
- continual learning
- task stream을 가정하지만 catastrophic forgetting이 큰 문제이며, 기존 task 성능 보존을 위해 추가 메모리/제약이 필요해진다.
- multi-task learning (MTL)
- 결론적으로, “성능은 fine-tuning 수준에 가깝게, 하지만 task별 추가 파라미터는 매우 작게, 그리고 task는 순차적으로 추가 가능”한 설계가 필요하다고 문제를 구체화한다.
이 논문이 목표로 하는 3가지 조건(요지)
- good performance
- sequential training (no simultaneous access to all tasks)
- parameter-efficient (task당 추가 trainable parameters가 매우 작음)
3) 이 논문에서 하는 새로운 기여는 무엇인가
- 핵심 기여는 Adapter modules를 BERT/Transformer에 삽입해 adapter tuning을 수행하는 구체 설계와, 그 설계가 다양한 NLP task에서 “full fine-tuning과 거의 같은 성능”을 “극히 적은 task-specific parameters”로 달성함을 대규모 실험으로 보인 것이다.
- 특히 기여를 더 구체적으로 쪼개면 다음이다.
-
- Adapter tuning 관점의 정식화
- 새 함수 \(\psi_{w,v}(x)\)를 구성하되,
- \(w\)는 pre-training에서 복사해 frozen
- \(v\)는 task별로 학습되는 작은 모듈 파라미터
- 초기 \(v_0\)는 \(\psi_{w,v_0}(x)\approx \phi_w(x)\) (near-identity) 가 되도록 둔다.
-
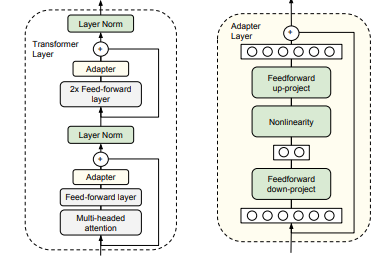
- Transformer에 대한 삽입 위치와 구조(bottleneck) 설계
- 각 Transformer layer에서 attention sub-layer 이후, feed-forward sub-layer 이후에 serial adapter를 삽입하는 구성을 제시한다(레이어당 2개 adapter).
-
- 성능-파라미터 효율 trade-off의 실증
- GLUE에서 full fine-tuning 대비 평균 성능 차이를 매우 작게 유지하면서(근소한 차이), task별 학습 파라미터 비율을 매우 낮게 제시한다.
- 추가 17개 분류 task + SQuAD에서도 유사한 경향을 보고한다.
-
- 분석/어블레이션
- adapter가 특히 higher layers에서 더 중요하게 작동하는 경향(하위 레이어 adapter 제거 영향이 작음)을 보고한다.
- initialization scale, 구조 변형 등에서 무엇이 중요한지(near-identity, bottleneck 등) 실험적으로 분해한다.
“compact”와 “extensible”의 의미(논문 맥락)
compact: task가 늘어도 task별 추가 파라미터가 작아 총 저장량 증가가 느리다.
extensible: 새 task를 추가할 때 backbone은 그대로 두고(adapter만 추가), 기존 task 성능에 영향을 주지 않는 방식으로 확장 가능하다.
4) 연구 방법은 무엇인가
4.1 Adapter tuning의 기본 아이디어(함수 관점)
- pre-trained network를 \(\phi_w(x)\)라고 하면,
- fine-tuning: task마다 \(w\) 자체를 변경한다.
- adapter tuning: 새로운 함수 \(\psi_{w,v}(x)\)를 정의하되,
- \(w\)는 고정(frozen)
- \(v\)만 학습(train)
- 초기에는 \(\psi_{w,v_0}(x)\approx \phi_w(x)\)가 되도록 설계(near-identity initialization)
직관적 의미
backbone 표현을 “완전히 다시 학습”하는 대신, backbone이 만든 feature를 task에 맞게 “작게 비틀어주는(thin adaptation layer)” 역할을 adapter가 수행한다.
그래서 성능을 유지하면서도 task별로 저장해야 하는 파라미터를 크게 줄일 수 있다.
4.2 Adapter module의 구조(bottleneck)
- 입력 feature dimension을 \(d\), bottleneck dimension을 \(m\)이라 두면 adapter는 다음 형태다.
- down-project: \(d \rightarrow m\)
- nonlinearity 적용
- up-project: \(m \rightarrow d\)
- adapter 내부에 skip-connection을 둬 전체적으로 near-identity가 되게 한다.
- 파라미터 수(레이어당, bias 포함)는 다음으로 제시된다.
- \(2md + d + m\)
- 핵심은 \(m\ll d\)로 두어, adapter가 매우 작게 되도록 만드는 것이다.
- 이때 task별 추가 파라미터는 backbone 전체에 비해 매우 작은 비율이 된다(논문은 0.5%~8% 같은 범위 언급).
bottleneck이 중요한 이유
\(m\)을 작게 두면 adapter의 표현력은 제한되지만, task별 파라미터는 강하게 압축된다.
논문은 “성능 저하 없이도 충분히 작은 \(m\)으로 near-fine-tuning 성능”이 가능함을 실험으로 보여주는 데 초점을 둔다.
4.3 Transformer(BERT)에서의 삽입 위치(architecture)
- Transformer layer는 (대략) 두 sub-layer로 구성된다.
-
- multi-head attention sub-layer
-
- feed-forward sub-layer
-
- 각 sub-layer는 “출력 → projection(입력 차원으로 복귀) → (residual/skip 더하기) → layer normalization” 흐름을 가진다.
- 논문 설계는 다음과 같이 serial adapter 2개/레이어를 넣는다.
- attention sub-layer 출력이 projection으로 \(d\) 차원으로 돌아온 직후, residual을 더하기 전에 adapter 삽입
- feed-forward sub-layer 출력이 projection으로 \(d\) 차원으로 돌아온 직후, residual을 더하기 전에 adapter 삽입
- 그리고 adapter 출력은 곧바로 다음 layer normalization으로 들어간다고 설명한다.
“projection 다음, residual 이전”이 의미하는 것
adapter가 residual path와 경쟁하는 것이 아니라, residual 합성 전에 “sub-layer가 만든 변화량을 task에 맞게 조정”하도록 설계한 것으로 이해할 수 있다.
결과적으로 backbone의 큰 구조를 유지하면서 작은 모듈로 조정하는 형태가 된다.
4.4 무엇을 학습하고 무엇을 고정하는가
- 고정(frozen)
- BERT/Transformer의 원래 파라미터 \(w\)는 고정한다.
- task별로 학습(train)
- adapter module 파라미터 \(v\)
- classification head(분류의 경우 [CLS] embedding 위에 linear layer)
- 그리고 논문은 task별로 layer normalization parameters도 학습 대상으로 포함한다고 명시한다.
- 비교 baseline으로 “layer normalization만 학습”도 고려하지만, 그것만으로는 성능이 충분하지 않다고 보고한다.
layer normalization을 task별로 두는 이유(직관)
Transformer에서 layer norm은 activation scale/shift를 조정한다.
adapter가 작기 때문에, layer norm까지 task별로 허용하면 “표현 분포를 task에 맞게 미세 조정”할 여지가 커진다.
4.5 실험 설정 요약(Optimization 포함)
- base model
- 공개된 pre-trained BERT를 사용한다.
- classification setup
- 입력 시퀀스 첫 토큰을 [CLS]로 두고, 그 embedding 위에 linear classifier를 붙이는 표준 절차를 따른다.
- optimizer / schedule
- Adam 사용
- warmup(학습 초반 일정 비율) 후 learning rate를 선형 감소시키는 스케줄을 사용한다고 서술한다.
4.6 핵심 실험 1: GLUE benchmark
- backbone: BERT-LARGE(24 layers, 330M parameters)
- 목적: adapter tuning이 full fine-tuning과 성능이 얼마나 가까운지, 그리고 파라미터 효율이 얼마나 좋은지 측정
- 결과 요지(논문이 대표 수치로 강조)
- GLUE 평균 성능에서 adapter가 full fine-tuning 대비 매우 근소한 차이로 근접한다.
- 하지만 task당 학습 파라미터 비율은 full fine-tuning(100%)에 비해 매우 작게 제시된다(대표 수치로 3.6%를 강조).
- “여러 GLUE task 전체를 풀기 위해 필요한 총 파라미터” 관점에서도,
- full fine-tuning은 task 수만큼 backbone이 복제되어 크게 증가
- adapter는 backbone은 1개로 공유되고 task별 adapter만 추가되어 총 증가가 작다
“trained params/task”와 “total params”가 다른 이유
trained params/task: 한 task를 학습할 때 실제로 업데이트되는 파라미터의 비율.
total params: 여러 task를 모두 다룰 수 있게 저장해야 하는 전체 파라미터(= 운영 관점 저장량).
adapter는 “학습량”도 줄지만, 특히 “총 저장량” 관점에서 이득이 커지도록 설계된 접근이다.
4.7 핵심 실험 2: 추가 17개 text classification task
- backbone: BERT-BASE(12 layers)
- 비교 baseline
- full fine-tuning
- variable fine-tuning: 상위 \(n\)개 layer만 fine-tune하고 나머지는 freeze (여러 \(n\)을 sweep)
- AutoML 기반 “no BERT” baseline(대규모 모델 탐색)
- 결과 요지
- adapter tuning 성능은 full fine-tuning에 매우 가깝다(평균 정확도에서 근소한 차이).
- full fine-tuning은 task 수만큼 backbone 저장이 필요해 total params가 매우 커지지만,
- adapter는 total params 증가가 작게 유지된다(표에서 total multiplier가 작게 제시됨).
- 해석 포인트
- variable fine-tuning은 “학습 파라미터를 줄이는” baseline으로 의미가 있으나,
- adapter는 “학습 파라미터 + 저장 파라미터 + 확장성”을 동시에 잡는 쪽으로 초점이 맞춰져 있다.
4.8 핵심 실험 3: SQuAD v1.1 (extractive QA)
- classification뿐 아니라 QA에서도 adapter가 유효함을 보인다.
- 결과는 full fine-tuning 대비 F1이 매우 근접한 수치로 제시된다(대표로 adapter size 64 설정에서 근소한 차이).
4.9 분석/어블레이션: 왜 되는가에 대한 단서
(a) 레이어별 adapter 중요도(제거 실험)
- 연속된 구간의 adapter를 제거했을 때 성능이 어떻게 무너지는지(heatmap 형태)로 분석한다.
- 관찰 요지
- 특정 single layer의 adapter를 제거하는 것은 대체로 영향이 작다.
- 하지만 adapter를 광범위하게 제거하면 성능이 크게 떨어진다.
- 특히 lower layers의 adapter 제거는 영향이 상대적으로 작고, higher layers의 adapter가 더 중요해 보이는 경향을 보고한다.
직관적 의미
BERT/Transformer에서 higher layers는 task-specific decision boundary에 더 가까운 high-level feature를 다루는 경향이 있다.
adapter tuning이 higher layers에서 더 중요하다는 관찰은 “task adaptation이 주로 상위 표현에서 일어난다”는 경험칙과 합치한다(논문은 이를 실험적으로 보여주는 쪽에 가깝다).
(b) initialization scale (near-identity의 필요성)
- adapter를 near-identity로 초기화하는 것이 안정적 학습에 중요하다고 주장하고, 초기화 스케일을 바꿔가며 성능 변화를 측정한다.
- 요지
- 초기화가 너무 크면 학습이 불안정하거나 성능이 크게 저하될 수 있다.
- 충분히 작은 스케일(near-identity에 가까움)에서는 비교적 robust한 경향을 보고한다.
(c) 구조 변형 탐색
- adapter depth 증가, normalization 추가, activation 변경, attention 내부에만 삽입, parallel adapter 등 여러 변형을 실험했다고 요약한다.
- 결론적으로, 논문이 제시한 “단순 bottleneck serial adapter”가 여러 데이터셋에서 강력했고, 더 복잡한 변형이 일관된 이득을 주지 않았다고 정리한다.
5) 한계는 무엇인가
-
- task 간 공동 학습을 통한 추가 성능 이득을 직접 목표로 하지 않는다.
- backbone을 frozen으로 유지하고 task별 모듈을 분리하므로, MTL처럼 task 간 정보 공유로 성능을 끌어올리는 프레임과는 목적이 다르다.
-
- “왜 higher layers adapter가 더 중요한가”에 대한 이론적 설명은 제한적이다.
- 논문은 주로 ablation/실험 관찰을 제시하며, 일반화된 메커니즘의 엄밀한 정식화는 중심 목표가 아니다.
-
- 설계의 효과는 BERT 중심 실험으로 강하게 뒷받침되지만,
- 다른 backbone/다른 modality/다른 학습 목표로의 일반화는 이 문서 범위에서는 제한적으로만 논의된다.
-
- initialization에 대한 민감성이 존재한다.
- near-identity에서 멀어지는 설정은 학습 안정성/성능에 악영향을 줄 수 있다고 보고한다.
-
- 운영 관점에서 “adapter bank 관리”가 필요하다.
- backbone 1개 + task별 adapter 모듈들을 저장/로딩/라우팅해야 하므로, 모델 운영 형태가 “단일 모델 파일”보다 복잡해질 수 있다(다만 총 저장량은 줄어드는 방향).
이 논문이 제공하는 실질적 결론(요지)
full fine-tuning 수준에 가까운 성능을 유지하면서,
task별로 저장해야 하는 파라미터를 “작은 adapter + (task별 layer norm + head)”로 제한해,
많은 task를 다루는 환경에서 총 모델 크기를 크게 줄일 수 있다는 것을 실험적으로 보여준다.