(1) 어떤 문제를 해결하고 싶은가
- 목표: multimodal(image/video + text) 모델이 few-shot in-context learning으로 새로운 시각-언어 태스크에 빠르게 적응하도록 만드는 것이다.
- “few-shot”은 태스크별 fine-tuning 없이, prompt에 (입력,정답) 예시를 몇 개(예: 4, 32 shots) 넣고 autoregressive generation으로 답을 생성하는 설정이다.
- 문제의 핵심 난점:
- 기존 CV 파이프라인은 대개 대량의 태스크별 라벨 데이터 + fine-tuning에 의존해서, 새로운 태스크/도메인에 빠르게 적응하기 어렵다.
- contrastive 기반 vision-language 모델(예: CLIP류)은 zero-shot 분류는 강하지만, 기본적으로 “text-image similarity”라서 언어를 생성해야 하는 open-ended 태스크(captioning, VQA, dialogue 등)에 제약이 있다.
- 텍스트 LLM처럼 few-shot을 하려면, 모델이 text 토큰 사이에 image/video 입력이 임의로 interleave될 수 있는 prompt를 처리해야 한다.
직관적 의미
“LLM이 텍스트만 보고 few-shot으로 태스크를 맞추는 것”을, “이미지/비디오를 prompt 중간중간 끼워 넣어도 같은 방식으로 few-shot을 하게 만들자”가 이 논문의 큰 방향이다.
(2) 선행연구는 어땠는가
- Fine-tuning 중심의 vision / vision-language:
- 대규모 supervised pretraining 후 태스크별 fine-tuning이 표준이고, 실무적으로는 수천~수십만 라벨이 필요할 때가 많다는 문제의식을 둔다.
- Contrastive vision-language(dual encoder):
- CLIP/ALIGN 계열처럼 contrastive objective로 zero-shot 분류/검색은 가능하나, 출력이 “생성”이 아니라 “유사도 점수”라 open-ended 생성 태스크에 직접 쓰기 어렵다.
- Visually-conditioned language generation:
- 이미지 조건부 생성/다중 모달 생성 연구들이 있었지만, low-data(few-shot)에서 강한 성능을 충분히 보여주지 못했다는 식으로 한계를 둔다.
- Frozen LM + adapter류 흐름:
- 큰 LM을 그대로 두고 일부 모듈만 학습해 catastrophic forgetting을 줄이는 흐름이 있으며, 이 논문도 “frozen LM을 기반으로 새로운 모달리티를 주입”하는 방향을 택한다.
왜 중요한지(왜 알아야 하는지)
이 논문은 “VLM에서 few-shot이 되려면 데이터(웹 기반 interleaved) + 아키텍처(이미지-텍스트 interleave 처리) + 학습전략(frozen backbone 연결)”이 동시에 맞아야 한다는 관찰을 강하게 밀고 간다.
(3) 이 논문에서 하는 새로운 기여는 무엇인가
- 핵심 기여:
- Visual Language Model(VLM) 패밀리 제안:
- image/video와 text가 arbitrarily interleaved된 입력을 받아 free-form text를 생성하고, 이를 few-shot prompting만으로 다양한 태스크에 적용한다.
- 아키텍처 기여:
- pretrained & frozen vision encoder와 pretrained & frozen LM을 “지식 손실을 최소화”하면서 연결하기 위해,
-
- Perceiver Resampler로 가변 길이 vision feature를 고정 개수 visual token으로 압축
-
- LM 블록 사이에 GATED XATTN-DENSE(학습 가능한 cross-attention + FFN, tanh gating) 삽입
-
- interleaved 입력에서 토큰마다 보게 할 visual token을 제한하는 per-image/video attention masking 도입
-
- pretrained & frozen vision encoder와 pretrained & frozen LM을 “지식 손실을 최소화”하면서 연결하기 위해,
- 학습 데이터 설계 기여:
- 웹에서 수집한 interleaved image-text 문서(M3W) + image-text pair(ALIGN, LTIP) + video-text pair(VTP) 혼합 학습이 few-shot 성능에 중요함을 실험적으로 보여준다.
- 폭넓은 few-shot 평가:
- 다수 image/video 벤치마크에서 few-shot 성능을 정리하고, 일부 태스크에서는 적은 shot으로도 strong supervised baseline에 근접/상회하는 결과를 보고한다.
- Ablation 기반 요인 분해:
- gating, cross-attn 구조, interleaved 데이터, 데이터 믹싱/최적화, 마스킹 전략, resampler 형태 등이 성능에 미치는 영향을 분해한다.
- Visual Language Model(VLM) 패밀리 제안:
(4) 연구 방법은 무엇인가
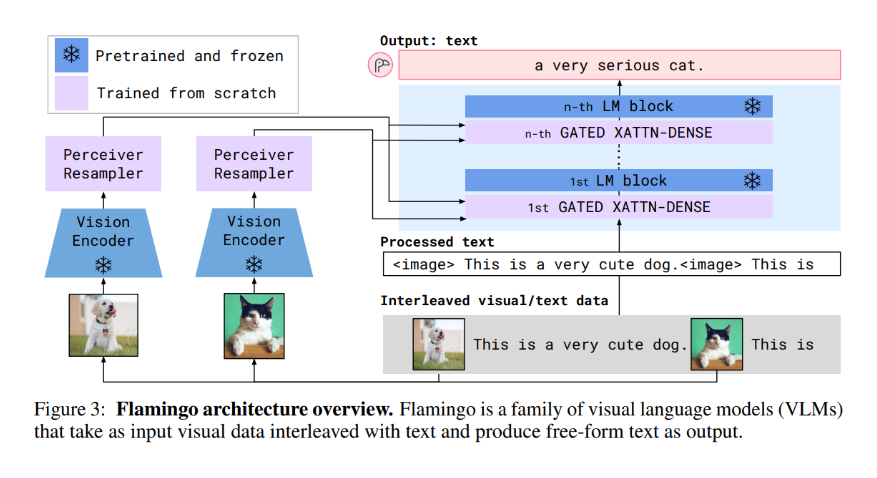
4.1 문제정의: interleaved vision-text 조건부 언어모델링
- 모델은 interleaved sequence에서 텍스트 \(y\)를 vision input \(x\)에 조건부로 생성한다.
- autoregressive factorization:
- \(p(y|x)=\prod_{\ell=1}^{L} p(y_\ell \mid y_{<\ell}, x_{\le \ell})\)
- \(x_{\le \ell}\)는 interleaved 순서에서 토큰 \(y_\ell\) 이전에 등장한 image/video들의 집합을 의미한다.
- autoregressive factorization:
- 중요 포인트:
- 많은 vision-language 태스크를 “정답 텍스트를 생성하는 next-token prediction”으로 통일해 다룬다.
직관적 의미
captioning/VQA/multiple-choice까지 전부 “prompt를 텍스트로 포맷팅하고, 필요한 곳에 image를 끼운 다음, 다음 토큰을 맞히는 문제”로 바꿔서 하나의 모델 인터페이스로 처리한다.
4.2 아키텍처
(A) Vision Encoder
- pretrained & frozen NFNet-F6를 vision encoder로 사용한다.
- image: 마지막 stage의 2D grid feature를 flatten해 1D sequence로 만든다.
- video: 1 FPS로 frame을 샘플링해 각 frame을 인코딩하고, temporal embedding을 더해 spatio-temporal feature를 구성한 뒤 flatten한다.
(B) Perceiver Resampler
- vision feature 길이는 해상도/프레임 수에 따라 커지므로, 이를 고정 개수(예: 64) visual tokens로 줄여 LM과의 cross-attention 비용을 줄인다.
- 방식:
- 학습된 latent queries(고정 개수)로 flatten된 vision feature에 cross-attention을 반복 적용하는 Perceiver 계열 구조를 사용한다.
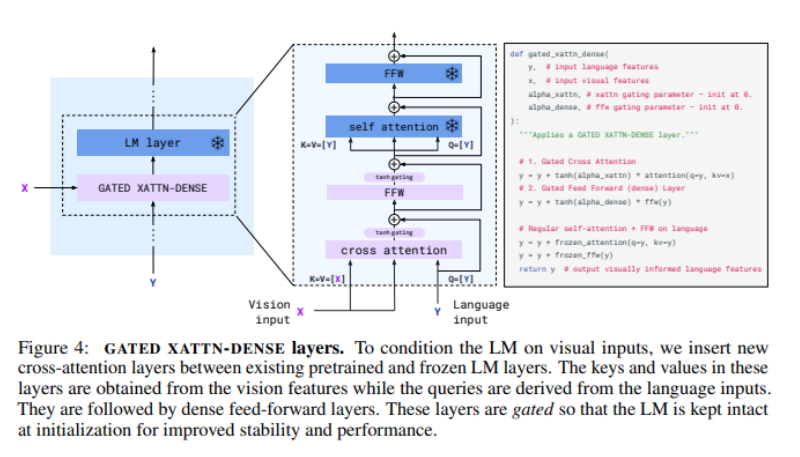
(C) Frozen LM + GATED XATTN-DENSE
- 텍스트 생성 backbone은 pretrained & frozen Chinchilla LM(여러 스케일) 계열을 사용한다.
- LM layer 사이사이에 학습 가능한 cross-attention + dense(FFN) 블록을 삽입한다.
- cross-attention: query는 language hidden \(Y\), key/value는 visual tokens \(X\).
- tanh gating + 0-init:
- 새 모듈의 출력에 \(\tanh(\alpha)\)를 곱하고 residual로 더한다.
- \(\alpha\)를 0으로 초기화하면 초기에는 원래 LM과 거의 동일하게 동작하도록 만들 수 있다.
왜 이 설계가 중요한가
pretrained LM을 “깨지 않게” 유지하면서(초기엔 동일), 학습이 진행될수록 필요한 만큼만 vision 정보를 쓰게 만드는 장치다. frozen backbone + 작은 trainable 모듈로 성능을 끌어올리는 전형적 패턴이다.
(D) Multi-visual input 마스킹
- interleaved 입력에서, 각 텍스트 토큰이 cross-attend하는 visual tokens를 직전 이미지/비디오 범위로 제한하는 마스킹을 둔다.
- 목표: 학습 시 제한된 개수의 이미지로도, 추론 시 더 많은 shots로 일반화 가능하게 하는 것.
4.3 학습 데이터와 학습목표
(A) 데이터 믹스
- 웹 기반 3종 데이터 혼합:
- M3W: 웹페이지에서 text와 images의 위치 정보를 이용해 image 태그를 삽입한 interleaved 문서 시퀀스
- Image-Text pairs: 대규모 pair 데이터(ALIGN 계열) + 더 길고 설명적인 자체 수집 pair(LTIP 계열)
- Video-Text pairs: short video와 문장 설명으로 구성된 자체 수집 데이터(VTP 계열)
- 메시지:
- interleaved 문서 데이터가 few-shot 능력에 특히 중요하고, pair 데이터가 보완적으로 중요하다는 결론을 제시한다.
(B) 학습목표
- 데이터셋별 NLL을 가중합으로 최소화:
- \(\sum_{m=1}^{M} \lambda_m \cdot \mathbb{E}_{(x,y)\sim \mathcal{D}_m}\Big[-\sum_{\ell=1}^{L}\log p(y_\ell \mid y_{<\ell}, x_{\le \ell})\Big]\)
- 최적화 전략:
- 데이터셋별 gradient를 계산해 accumulation으로 합치는 방식이 더 낫다는 실험적 주장(데이터 믹싱 방식 ablation).
4.4 Few-shot 평가 프로토콜
- in-context learning:
- support 예시(support set)를 interleaved prompt로 구성한 뒤 query에 대한 출력을 생성한다.
- open-ended:
- 생성 기반 decoding으로 정답 텍스트를 생성한다.
- close-ended(예: multiple-choice):
- 후보 답을 각각 붙여 log-likelihood로 점수화해 랭킹한다.
- 큰 support pool에서 예시 선택:
- 비슷한 예시를 골라 prompt 길이를 제한하는 retrieval 기반 선택(RICES)을 사용한다.
(5) 한계는 무엇인가
- 주요 한계(논문이 논의하는 축):
- LM 약점 상속:
- hallucination/ungrounded guess 위험, 긴 시퀀스 일반화의 어려움.
- Classification에서 contrastive 대비 약점 가능:
- language modeling objective가 retrieval/분류에 직접 최적화된 contrastive objective에 비해 불리할 수 있다.
- In-context learning의 구조적 제약:
- prompt sensitivity(포맷/순서/데모 선택에 민감), shot 수 증가 시 inference compute 증가, 성능 plateau 가능성.
- 데이터/재현성 제약:
- 대규모 웹 데이터/모델 학습 세부가 공개되지 않을 경우 재현이 어렵다.
- Societal risk:
- 웹 데이터 기반 bias/toxicity/PII 위험, 시각 입력까지 포함되며 편향 증폭 가능성.
- LM 약점 상속:
실무적 해석(왜 중요한지)
Flamingo의 few-shot 성능은 “아키텍처”만으로 설명되지 않고, interleaved 데이터와 prompting 프로토콜이 결합된 결과로 제시된다. 재현/확장에서는 데이터 믹스와 prompt 포맷이 어긋나면 성능이 쉽게 붕괴할 수 있다는 점이 핵심 리스크다.