1) 어떤 문제를 해결하고 싶은가
- 이 연구의 핵심 문제는 Video Large Multimodal Models (VLMMs) 가 video와 text를 충분히 잘 정렬(alignment)하지 못해서, 영상에 제대로 grounded되지 않은 답변을 자주 만든다는 점이다. 특히 기존 VLMM은 대개 Supervised Fine-Tuning (SFT) 으로 학습되는데, multimodal instruction-tuning data는 text-only data보다 양과 질이 모두 부족해서 visual/temporal grounding이 약해진다고 본다.
- 저자들은 이 문제를 “모델이 말을 잘하는가”의 문제가 아니라, 영상 내용에 맞는 선호(preference)를 어떻게 학습시키느냐의 문제로 본다. 즉, video를 보고 생성한 여러 답변 중 어떤 답변이 더 적절한지에 대한 signal이 부족하다는 것이다.
- 그래서 목표는 단순히 instruction-following 능력을 높이는 것이 아니라, video content에 더 정확히 grounded된 응답을 만들도록 VLMM을 정렬하는 것이다. 이를 위해 사람 피드백 대신 AI feedback을 이용한 RLAIF (Reinforcement Learning from AI Feedback) 를 video domain에 적용한다.
직관적 의미
기존 SFT 기반 VLMM은 “그럴듯한 문장”은 만들 수 있지만, 실제 video에 없는 내용을 지어내거나 temporal detail을 틀리는 경우가 있다.
이 논문은 “어떤 답이 video에 더 잘 맞는가”를 AI가 스스로 비교하게 만들고, 그 비교 결과를 reward로 바꿔 다시 모델을 강화하는 방식으로 문제를 푼다.
왜 중요한가
Video understanding에서는 object, action, temporal order, context가 동시에 맞아야 한다.
조금만 grounding이 약해도 VideoQA, description generation, retrieval, action recognition 전반에서 성능이 무너진다.
따라서 “video에 맞는 답변을 선호하도록 학습하는 것”은 단일 task가 아니라 전반적 video-text alignment 문제의 핵심이다.
2) 선행연구는 어땠는가
- 기존 Multimodal large model 계열은 보통 pretrained visual encoder를 붙이고, 그 representation을 LLM token space로 projection한 뒤, synthetic multimodal instruction-tuning data로 SFT 하는 방식이 주류였다. 본문에서는 Video-ChatGPT, Video-LLaVA, LLaMA-VID 같은 video VLMM 계열을 이러한 흐름 위에 둔다.
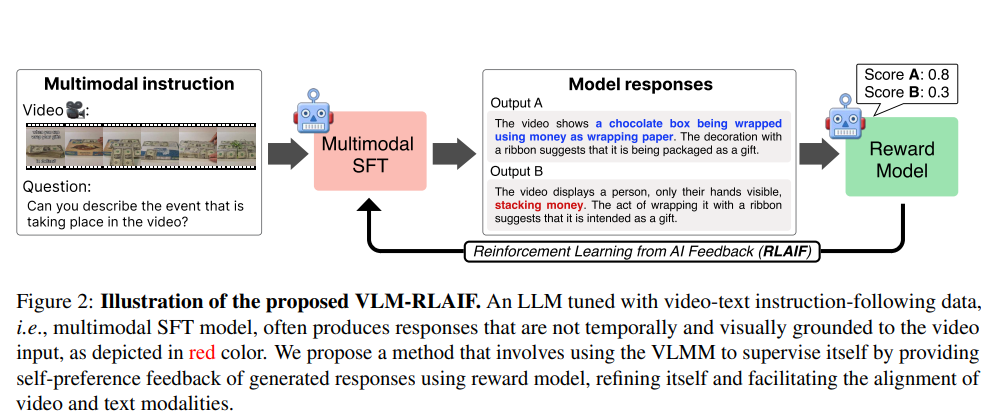
- 이 접근은 기본적인 instruction-following과 conversation capability는 확보하지만, 저자들에 따르면 video grounding, 특히 temporal detail 과 contextual correctness 가 충분하지 않다. 논문 1, 2페이지와 Figure 2는 SFT 모델이 video와 어긋난 응답을 생성하는 예를 직접 보여준다.
- 한편 language model alignment에서는 RLHF (Reinforcement Learning from Human Feedback) 가 널리 쓰였고, reward model을 학습한 뒤 policy를 RL로 개선하는 틀이 이미 자리 잡고 있었다. 하지만 multimodal/video setting에서 RLHF를 그대로 쓰기에는 human preference annotation cost 가 크다.
- 이를 보완하기 위해 RLAIF 가 제안되었는데, 이는 사람 대신 AI가 preference를 생성하는 방식이다. 다만 이 논문 이전에는 주로 text-only 또는 image-text 쪽이 중심이었고, video VLMM alignment에 맞춘 context-rich preference modeling 은 충분히 정리되어 있지 않았다고 볼 수 있다.
- 또한 기존 VLMM 학습은 instruction data 자체가 제한적이라, SFT만으로는 고품질 alignment를 만들기 어렵다. 저자들은 그래서 추가 instruction-tune data augmentation 과 curriculum learning 도 함께 필요하다고 본다.
선행연구의 한계 요약
- SFT-only: video에 대한 문장 생성은 가능하지만 grounding이 약하다.
- RLHF: 효과적이지만 사람 선호 라벨이 비싸고 확장성이 낮다.
- 기존 RLAIF: scalable하지만, video 특유의 temporal/context difficulty를 제대로 반영한 설계가 부족하다.
- 기존 VLMM data pipeline: multimodal instruction data가 부족해 alignment 자체가 약하다.
3) 이 논문에서 하는 새로운 기여는 무엇인가
- 가장 큰 기여는 video VLMM에 특화된 RLAIF framework 를 제안했다는 점이다. 저자들은 이를 VLM-RLAIF 라고 부른다. 즉, AI가 만든 preference feedback 으로 reward model을 학습하고, 그 reward를 최대화하도록 policy를 RL로 미세조정한다.
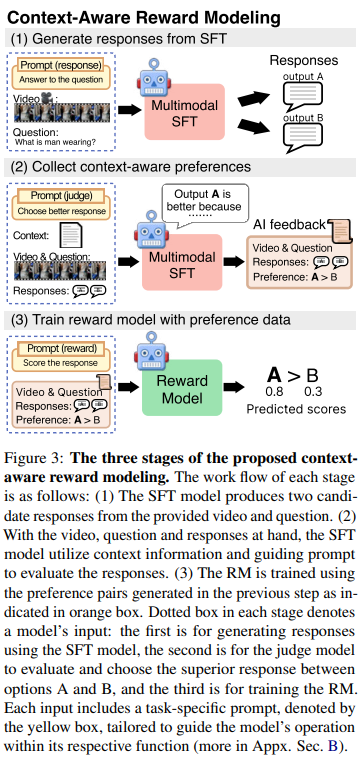
- 두 번째 핵심 기여는 context-aware reward modeling 이다. 단순히 “question + answer A + answer B”만 보고 선호를 고르게 하지 않고, video를 clip으로 나누어 만든 detailed narrative context 를 judge model에 함께 넣는다. 이것이 video content에 대한 더 정교한 선호 판단을 가능하게 만든다는 주장이다. Figure 3, Figure 4가 이 workflow를 설명한다.
- 세 번째 기여는 SFT data augmentation + two-stage curriculum SFT 이다. 기존 open-source video-text instruction data에 더해, human-labeled VideoQA dataset과 object-centric narrative 기반 instruction-tune data를 추가하고, 쉬운 샘플에서 어려운 샘플로 가는 2-stage curriculum을 적용한다.
- 네 번째 기여는 empirical validation이다. Video-based generative benchmark, zero-shot VideoQA, text-to-video retrieval, zero-shot action recognition 등 여러 benchmark에서 기존 VLMM과 자체 SFT baseline보다 일관되게 우수한 성능을 보인다. 특히 7B policy임에도 13B SFT baseline을 넘는 결과가 강조된다.
이 논문의 novelty를 한 줄로 말하면
“video를 더 잘 이해하도록 AI가 AI를 평가하게 만들되, 그 평가 과정에 detailed video context를 넣어서 reward를 더 grounded하게 만든다”가 핵심이다.
4) 연구 방법은 무엇인가
전체 파이프라인
- 전체 학습 절차는 크게 3단계다.
- VLM-SFT 를 만든다.
- 이 모델을 이용해 AI preference data 를 생성하고 Reward Model (RM) 을 학습한다.
- 학습된 RM을 이용해 PPO 로 policy model을 RL fine-tuning한다.
- 논문 3페이지는 이 절차를 명시적으로 정리한다. 먼저 SFT를 수행하고, 이어서 SFT model을 judge로 사용해 preference를 생성하고, 마지막에 PPO로 reward를 최적화한다.
왜 3단계가 필요한가
SFT는 “기본적으로 대답하는 능력”을 만든다.
Reward modeling은 “어떤 답이 더 좋은지 판단하는 기준”을 만든다.
RL은 “좋은 답을 더 자주 생성하도록 policy를 실제로 바꾸는 단계”다.
(1) Supervised Fine-Tuning: VLM-SFT
- 기본 backbone은 pretrained image-text model 위에 video projection layer를 얹는 구조다. 논문은 두 개의 linear layer + ReLU 로 구성된 video projection layer를 사용하고, LoRA 로 추가 학습을 수행한다.
- video input은 각 video에서 50 frames 를 uniform sampling하고, CLIP visual encoder 로 spatial/temporal feature를 추출한다.
- SFT 데이터는 세 부류를 사용한다.
- [A] 기존 open-source video-text instruction-tune data 80k
- [B] human-labeled VideoQA data 67k
- [C] object-centric narrative 기반 generated instruction-tune data 180k
총합 관점에서 SFT training set을 크게 확장했다.
- 여기에 two-stage curriculum learning 을 적용한다. 데이터 난이도를 answer length 로 정의하고, 짧은 답변을 요구하는 쉬운 샘플부터 학습한 뒤 긴 답변을 요구하는 어려운 샘플로 넘어간다. 저자들은 긴 답변이 더 깊은 comprehension과 더 복잡한 sentence generation을 요구한다고 본다.
- 실제 분할은 easy 214k, hard 113k이며, stage별로 1 epoch씩 학습했다. LoRA rank와 α는 둘 다 32다.
직관적 의미
이 단계는 모델에게 “video를 보고 기본적으로 말하는 법”을 가르치는 단계다.
특히 object-centric data를 추가한 것은, video 안의 object appearance/action/location을 더 세밀하게 묻고 답하게 만들기 위한 장치다.
(2) Context-aware Preference Selection
- 단순 preference selection이 아니라 context-aware 방식으로 preference를 만든다.
- 구체적으로는 video를 여러 작은 clip으로 분할하고, 각 clip마다 VLM-SFT에
"Describe this video in detail"prompt를 주어 detailed description 을 생성한다. 이 clip-level caption들을 이어 붙여 narrative context 를 만든다. - 그 다음, 동일한 video-question pair에 대해 SFT 모델이 생성한 두 candidate response 를 준비하고, judge prompt와 함께 video + question + responses + context 를 넣어 어느 답변이 더 좋은지 선택하게 한다. Figure 3과 Figure 4가 이 과정을 단계적으로 설명한다.

- Figure 4의 예시를 보면, SFT가 만든 두 응답 중 하나는 “100kg에서 실패했다” 같은 잘못된 detail을 포함하고, 다른 하나는 video 내용에 더 맞는다. context를 함께 제공한 judge model은 후자를 선호하며 그 이유도 설명한다. 즉, 선호 자체가 video-grounded justification을 반영하게 된다.
왜 context가 필요한가
video encoder만으로는 긴 영상의 temporal nuance를 다 담기 어렵다.
clip 단위 설명을 붙여 만든 narrative context는 judge에게 “영상에서 실제로 무슨 일이 벌어졌는지”를 더 선명하게 제공한다.
즉, preference signal의 품질을 높이는 역할을 한다.
(3) Reward Model 학습
- RM은 응답 하나에 scalar reward를 주는 모델이다. 출발점은 VLM-SFT이며, 마지막 linear layer를 제거한 뒤 reward scorer처럼 사용한다. 입력은 prompt와 response이고 출력은 scalar reward다.
- 학습 데이터는 앞 단계에서 얻은 pairwise preference다. 즉, 같은 question에 대한 두 답변 A, B 중 어느 쪽이 더 나은지에 대한 라벨을 사용한다. 학습은 Bradley-Terry model 에 기반한 cross-entropy loss 로 수행한다. 더 좋은 답변에는 더 높은 score가 가도록 학습한다.
- 저자들은 7B보다 13B SFT judge가 약간 더 낫다는 분석에 근거해 13B VLM-SFT 기반 RM 을 채택한다. 실험에서도 13B RM이 7B RM보다 대체로 더 좋은 결과를 준다.
RM의 역할
RM은 “좋은 답변인지 아닌지”를 수치화한 함수다.
이 수치가 있어야 PPO가 어떤 방향으로 policy를 업데이트할지 정할 수 있다.
(4) Reinforcement Learning with PPO
- 마지막으로 policy model을 VLM-SFT로 초기화하고, value model은 RM으로 초기화한 뒤 PPO (Proximal Policy Optimization) 로 reward를 최대화하도록 RL fine-tuning한다.
- RL 단계에서는 QLoRA 를 사용해 계산 효율을 높였고, rank 64, α 16으로 1 epoch 학습한다. 전체 학습은 8×NVIDIA A100 80GB 에서 수행했다.
(5) Object-centric Instruction-tune Data 생성
- Appendix A는 추가 데이터 생성 방식을 자세히 설명한다. 저자들은 Video Localized Narratives dataset을 사용해 object별 appearance/action/trajectory가 포함된 narrative caption을 확보한다. 그리고 이를 ChatGPT 에 넣어 question-answer pair 형식의 instruction-tune data로 바꾼다.
- 생성 prompt는 “Narrations를 보고 대화형 질문 5개와 답변 5개를 만들어라”는 형식이며, 질문은 appearance, motion, trajectory, reasoning을 다루도록 설계되어 있다. Appendix의 Figure 7이 구체 예시를 보여준다.
- 이 부분은 모델이 video의 object-level detail과 event-level relation을 더 잘 배우도록 하는 data engineering contribution으로 볼 수 있다.
5) 실험 결과는 무엇을 보여주는가
(1) Video-based generative benchmark
- Table 1에서 VLM-RLAIF(7B)는 VLM-SFT(7B) 대비 모든 지표에서 개선된다.
- Correctness: 2.79 → 3.63
- Detail: 2.82 → 3.25
- Context: 3.37 → 4.00
- Temporal: 2.28 → 3.23
- Consistency: 2.49 → 3.32
- 즉, 단순히 한두 항목이 아니라 정확성, 세부묘사, 맥락, 시간 이해, 일관성 전부가 좋아진다. 논문 주장대로라면 reward learning이 “더 grounded한 응답”을 선호하게 만들었기 때문이다.
(2) Zero-shot VideoQA
- Table 2에서 세 benchmark 모두 개선된다.
- MSVD-QA: Acc 67.2 → 76.4, Score 3.6 → 4.0
- MSRVTT-QA: Acc 52.4 → 63.0, Score 3.0 → 3.4
- ActivityNet-QA: Acc 44.1 → 57.3, Score 3.2 → 3.5
- 특히 accuracy 기준으로 +9.2%, +10.6%, +13.2% 향상이라고 논문이 직접 강조한다. 즉, answer generation의 grounding 개선이 question answering capability로도 이어진다.
(3) Text-to-Video retrieval / Action recognition
- Table 3에서도 retrieval과 recognition 양쪽 다 improvement가 있다. 예를 들면
- MSVD retrieval R@1: 26.65 → 36.03
- MSRVTT retrieval R@1: 13.10 → 21.00
- UCF101 Top-1: 53.03 → 62.83
- HMDB51 Top-1: 38.58 → 44.75
- 이 점은 중요한데, 이 모델이 단지 generative description만 좋아진 것이 아니라 downstream representation quality나 alignment quality 자체 가 좋아졌음을 시사한다. 다만 이 해석은 논문의 결과를 바탕으로 한 합리적 inference다.
6) Ablation과 분석에서 무엇을 확인했는가
(1) SFT data augmentation + curriculum learning의 효과
- Table 4에 따르면
- 기본 [A]만 사용: Correctness 2.32
- [A]+[B]+[C] 추가: 2.43
- 여기에 curriculum learning 추가: 2.79
로 올라간다. 다른 지표도 함께 개선된다.
- 따라서 단순히 RL만 잘한 것이 아니라, SFT stage 자체를 더 좋은 data와 curriculum으로 강화한 것도 중요한 성능 요인이다.
(2) Context-aware preference의 효과
- Table 5는 context를 넣지 않은 RLAIF와 넣은 RLAIF를 비교한다.
- SFT baseline: Correctness 2.79
- RLAIF, context 없음: 3.26
- RLAIF, context 있음, 1 clip: 3.44
- RLAIF, context 있음, 3 clips: 3.63
- 즉, RLAIF 자체도 효과가 있지만 context-aware preference가 추가로 의미 있는 개선을 준다. 그리고 video를 여러 clip으로 나누어 context를 만들수록 더 좋았다. 이는 긴 video의 nuance를 narrative로 풀어 judge에게 넘기는 설계가 실제로 동작함을 지지한다.
(3) Preference data size의 효과
- Figure 5에 따르면 preference data를 10k에서 40k로 늘릴수록 다섯 지표가 monotonic 하게 증가한다. 즉, synthetic preference data를 많이 모을수록 reward learning 성능이 계속 좋아진다.
- 이는 RLAIF의 장점인 scalability 를 실험적으로 뒷받침한다. human preference였다면 이런 규모 확장이 훨씬 더 비쌌을 것이다.
(4) Reward model size의 효과
- Table 7, 8에서 13B RM이 대체로 7B RM보다 낫다. policy는 동일하게 7B인데 reward model만 키워도 성능이 더 좋아진다.
- 이는 “policy를 무작정 키우는 것”보다도, 더 정확한 evaluator/reward model 이 alignment에 중요하다는 해석을 가능하게 한다. 다만 논문은 이 점을 직접 이론화하지는 않고 empirical observation으로 제시한다.
7) 이 논문을 쉽게 요약하면
- 기존 VLMM은 video를 보고도 그럴듯하지만 틀린 말을 자주 한다.
- 저자들은 같은 video-question에 대해 여러 답변을 만들고, AI judge가 어떤 답이 더 video에 맞는지 선택하게 했다.
- 이때 judge가 video를 더 잘 이해하도록, video를 clip으로 나눠 만든 detailed context 를 함께 보여줬다.
- 그렇게 모은 preference로 reward model 을 만들고, 최종 모델을 PPO 로 강화학습했다.
- 결과적으로 모델은 더 정확하고, 더 자세하고, 더 temporal하게 맞는 답변을 생성하게 되었다.
핵심 메시지
이 논문은 “video VLMM을 더 잘 만들려면 data만 늘릴 게 아니라, 어떤 답이 더 영상에 맞는지 평가하는 signal 자체를 개선해야 한다”는 입장이다.
그리고 그 평가 signal을 사람 대신 AI가 만들되, context-aware 하게 만들어 품질을 보완했다는 점이 핵심이다.
8) 한계는 무엇인가
- 논문이 직접 인정하는 첫 번째 한계는, 이 방법이 AI가 생성한 feedback의 품질 에 크게 의존한다는 점이다. judge model이 잘못된 preference를 만들면 reward model도 오염되고, 결국 RL도 잘못된 방향으로 갈 수 있다. 즉, synthetic feedback quality가 병목이다.
- 두 번째 한계는 benchmark coverage다. 저자들은 VideoQA, generative task, retrieval, recognition은 평가했지만, temporal reasoning 같은 더 까다로운 real-world video understanding task는 아직 충분히 다루지 못했다고 말한다.
- 추가로 논문을 읽고 추론할 수 있는 실무적 한계도 있다.
- clip 분할 후 caption을 생성하고 이를 다시 judge에 넣는 과정은 pipeline이 길고 계산비용이 증가할 수 있다.
- context 자체도 결국 VLM-SFT가 만든 description이므로, context가 잘못 생성되면 preference selection도 흔들릴 수 있다.
- difficulty를 answer length 로 정의한 curriculum은 간단하지만, 진짜 semantic difficulty를 충분히 반영하지 못할 수 있다.
이 중 앞의 두 항목은 방법 구조상 자연스러운 해석이고, 마지막 항목도 설계상 타당한 비판이지만, 논문이 직접 강하게 실험 검증한 부분은 아니다.
한계의 본질
이 논문은 “AI를 evaluator로 쓰면 scalable하다”는 장점을 얻는다.
대신 “그 evaluator가 틀리면 전체 alignment가 같이 틀릴 수 있다”는 구조적 리스크를 안고 간다.
즉, human cost를 줄이는 대신 evaluator reliability 문제가 남는다.
9) 최종 정리
- 해결하려는 문제: video-text alignment 부족으로 인한 ungrounded response 생성
- 선행연구: SFT 기반 VLMM 과 RLHF/RLAIF 가 있었지만, video에 특화된 고품질 preference 설계가 약했다.
- 새로운 기여:
- VLM-RLAIF 제안
- context-aware reward modeling 제안
- instruction data augmentation + two-stage curriculum SFT 제안
- 연구 방법:
- SFT로 base VLMM 학습
- clip-level description을 모아 context 생성
- AI judge로 preference 수집
- Bradley-Terry 기반 RM 학습
- PPO로 policy RL fine-tuning
- 결과: VideoQA, generative benchmark, retrieval, action recognition 전반에서 자체 SFT와 기존 VLMM 대비 우수
- 한계: AI-generated feedback quality dependence, 평가 범위의 제한, context pipeline의 잠재적 오류 전파 가능성