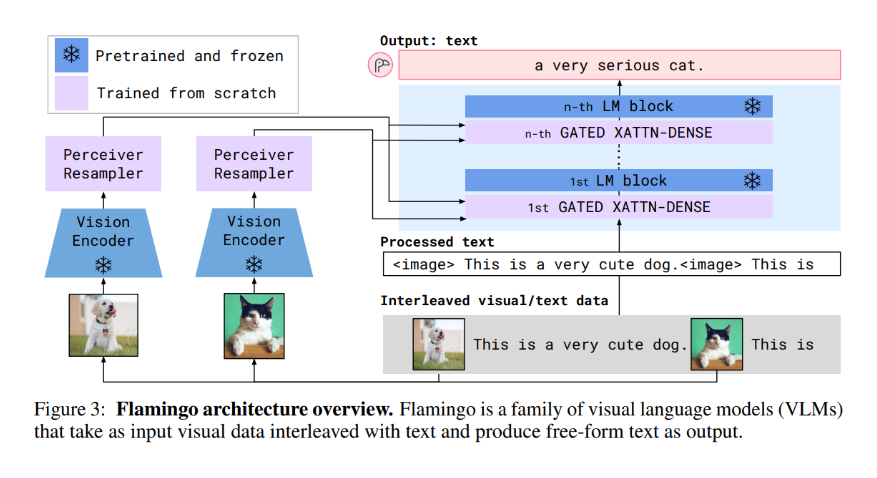
(1) 어떤 문제를 해결하고 싶은가목표: multimodal(image/video + text) 모델이 few-shot in-context learning으로 새로운 시각-언어 태스크에 빠르게 적응하도록 만드는 것이다.“few-shot”은 태스크별 fine-tuning 없이, prompt에 (입력,정답) 예시를 몇 개(예: 4, 32 shots) 넣고 autoregressive generation으로 답을 생성하는 설정이다.문제의 핵심 난점:기존 CV 파이프라인은 대개 대량의 태스크별 라벨 데이터 + fine-tuning에 의존해서, 새로운 태스크/도메인에 빠르게 적응하기 어렵다.contrastive 기반 vision-language 모델(예: CLIP류)은 zero-shot 분류는 강하지만, 기본적으로..