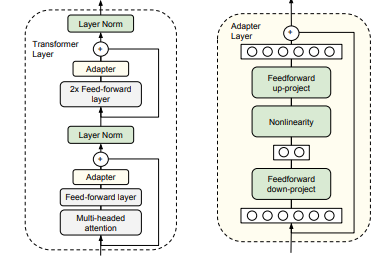
1) 어떤 문제를 해결하고 싶은가목표는 Transfer Learning에서 “task가 많아질수록 모델 저장/학습 비용이 task 수에 비례해 폭증”하는 문제를 줄이는 것이다.대형 pre-trained model(예: BERT)을 각 downstream task마다 full fine-tuning하면, 사실상 task마다 새로운 모델 전체 사본이 필요해진다.online/streaming 환경(새 task가 순차적으로 계속 추가되는 환경)에서는,과거 task를 다시 같이 학습하지 않고도(sequential training)새 task를 추가하면서도저장/메모리/배포 비용이 과도하게 증가하지 않는(parameter-efficient)방식이 필요하다.왜 이 문제가 중요한가대형 backbone을 task마다 통째로..