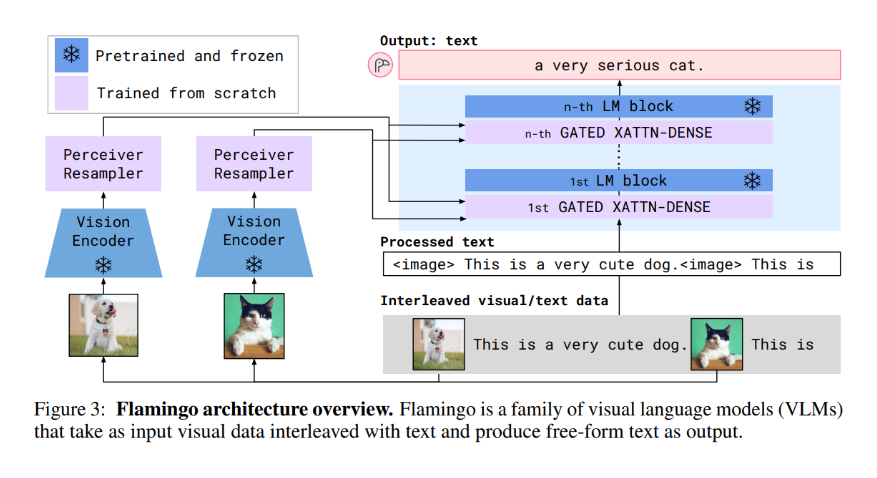
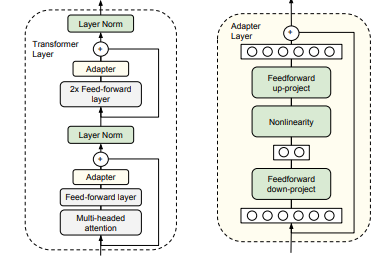
📋핵심이 논문은 “각 사용자(클라이언트)가 서로 다른 멀티모달 작업을 하고(데이터가 다름), 심지어 서로 다른 모델을 쓰는(모델 구조/크기가 다름) 현실적인 연합학습 환경에서, 어떻게 서로 도와서 개인화 성능을 올릴까”를 다룬다.핵심 아이디어는 두 가지로 요약된다. 1. 아무나 섞지 말고, 나랑 비슷한 클라이언트 것만 많이 섞자각 클라이언트의 데이터(작업)가 얼마나 비슷한지 “관련도(relevance)”를 추정해서, 관련도가 높은 클라이언트의 업데이트는 크게, 낮은 클라이언트의 업데이트는 작게 반영한다. 그래서 서로 다른 작업을 무작정 평균내서 생기는 성능 하락(interference)을 줄인다. 2. 모델이 달라도 공유 가능한 ‘공통 부품’만 공유하자모델 구조가 다르면 보통 파라미터를 그대로 합칠 수..